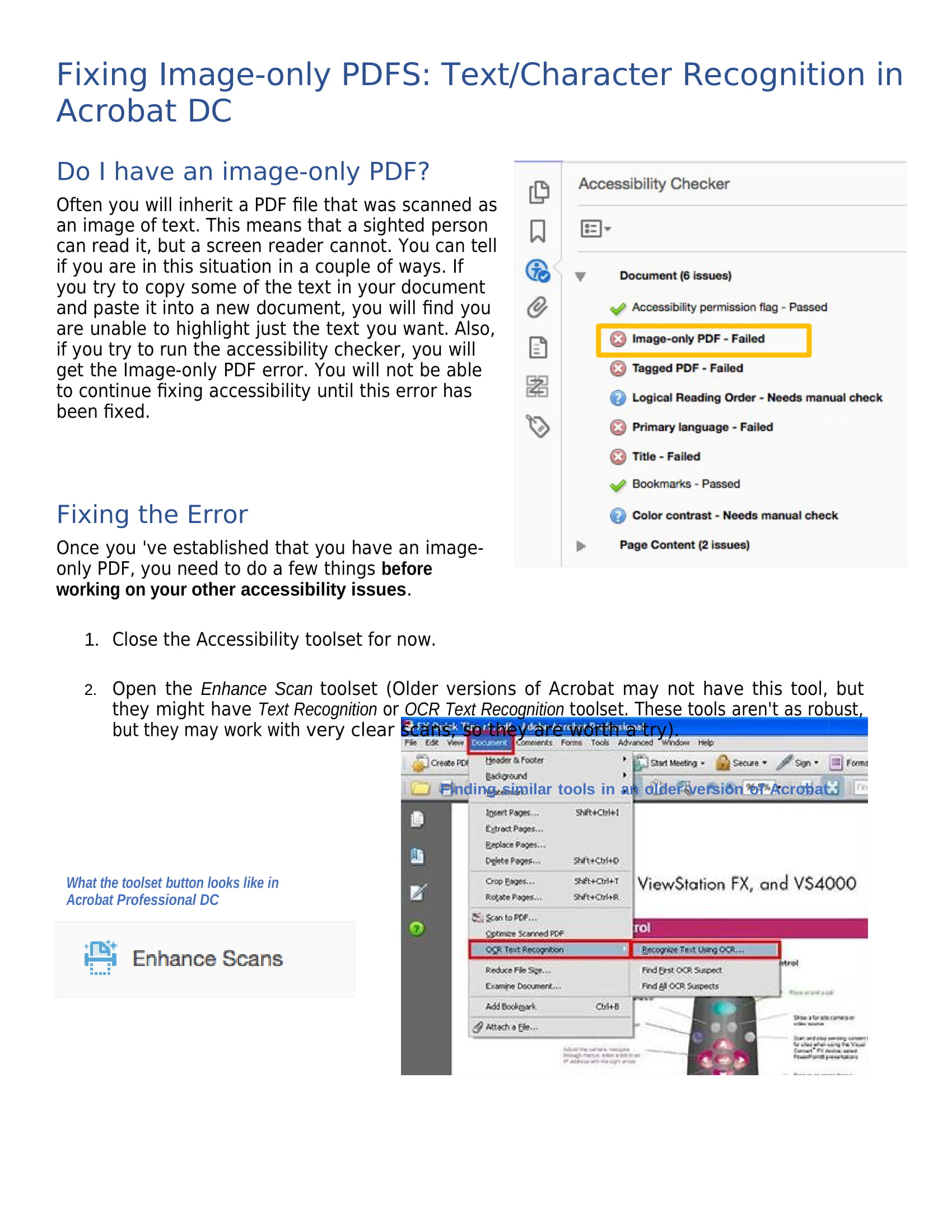
We’ve used OpenCV on the scanned document image to get the contours of the objects found in that image, which mainly should be fragments of text or other images.
The results contain both text fratements and images and we can filter them based on their height, for example, to eliminate most text fragements.
Some results:
- Large font, large logos.

Result:

- An invoice

Result:




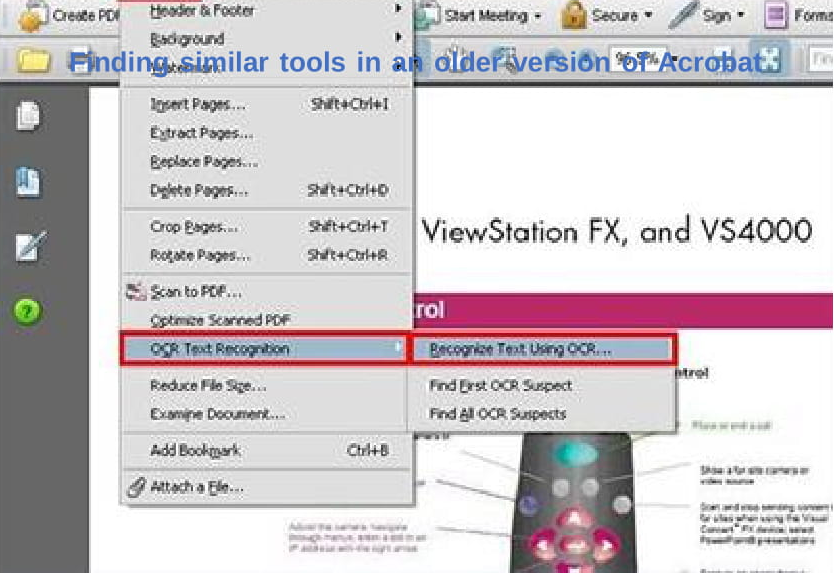
- Small text, text overlapping image, images with various backgrounds (the objects need to have different foregrounds that the image background)
Result: