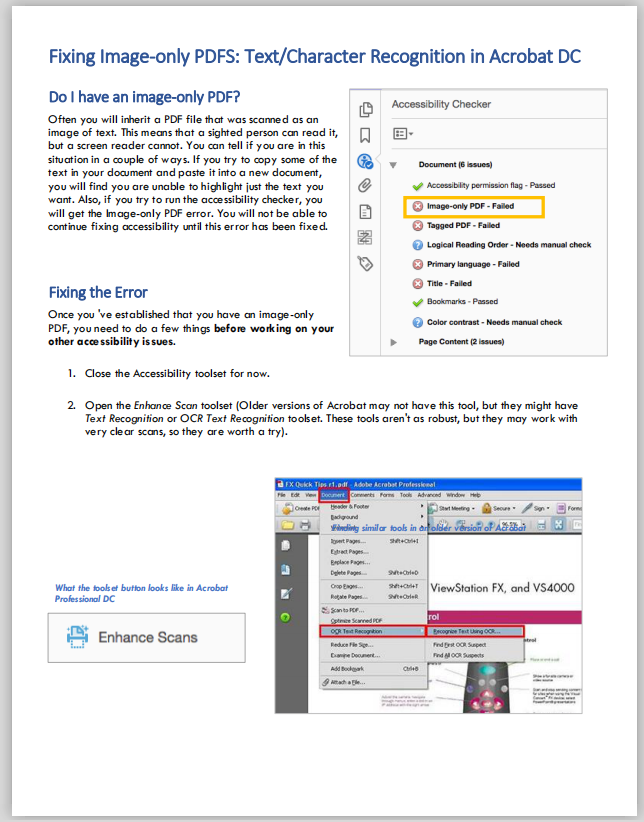
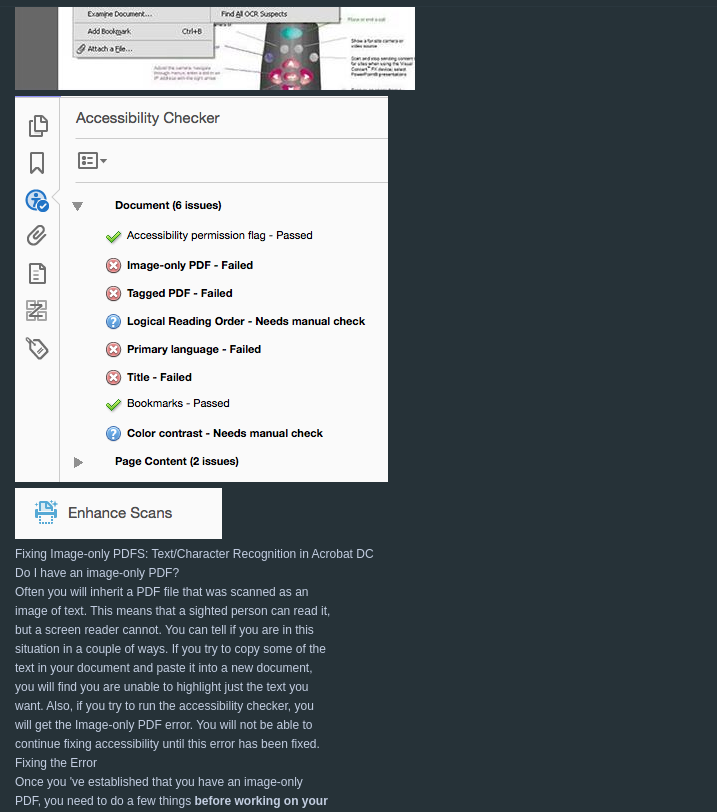
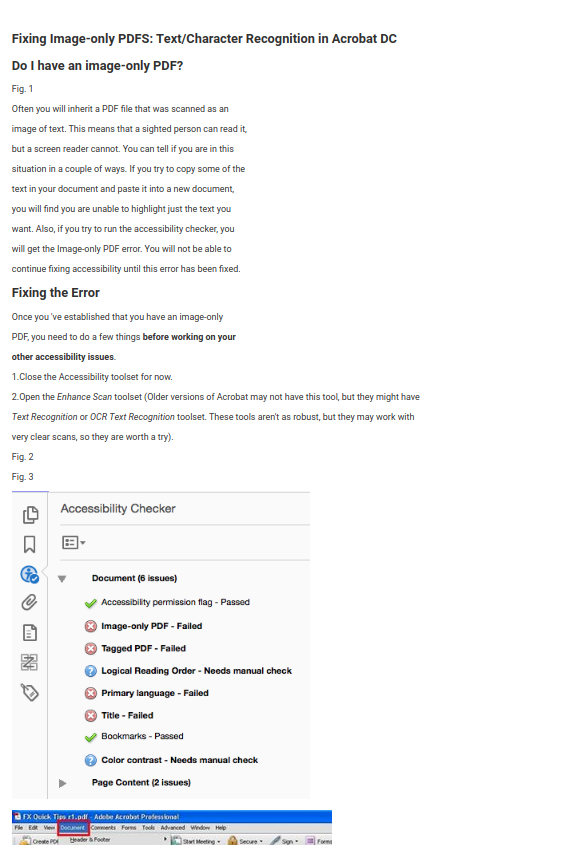
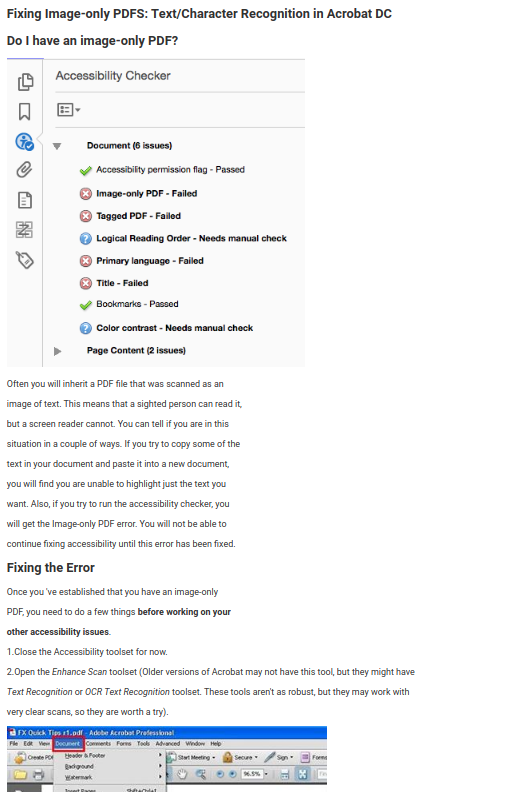
For documents containing images when converting to markdown, we got a few options:
- extract the images, remove them from the document and keep the text format/indentation
- extract the images on top of each page
- extract the images and try to place them somewhere in the page
Given that markdown does not contain styles we cannot place the text and the image side by side, how should we treat this case?
For this document the results for the first 2 options you’ve listed:
First option result:
Second option result:
This option fails to maintain the font sizes but keeps the text indentation and placement in the page.
It seems the aspect of the document changes quite a lot, even if we eventually match the font type and size, perfect imitation can not be achieved. Can we instead add a place holder where the image was with a label to reference the attached graphic that would be placed on the same page in footer? Similar to adding references as foot notes in s scientific paper.
Following your advice we have got this result:
Hovering on images will tell the ‘Fig.’ number.
We can also go with this approach where the images are aligned to the left and push the content down:
I like the former version, because it focuses attention on the content. However we might face difficulties with footnotes support depending on how we export these.
The later version seems straight forward without any complications. Let’s see more opinions.
Be interesting to know how OpenOffice does it with PDF import, and whether there’s any mileage in using an OpenOffice server to do a conversion just for the layout.
The problem is not related to the PDF, it is that we are using Markdown for the processed file (so any document is converted to Markdown in the end) and it does not support columns in the layout, so we have to change the layout of the original document. This issue is not limited to images either, same problem with 2 columns of text layouts.
Been thinking about this and ways to utilise the internals of a given “starting” doc to recreate the structures at the end. Requires a way to “hide” tags in the document view, which can be utilised as placemarkers to match with the original document’s skeleton.